Unveiling MUMU: Bridging Text and Image for Creative AI
In the ever-evolving world of artificial intelligence, the ability to generate images from textual descriptions has taken a significant leap forward with the introduction of MUMU. This new model is designed to handle multimodal prompts, which means it can take both text and images as inputs to create coherent and visually appealing outputs.
What is MUMU?
MUMU stands for a model that bootstraps multimodal image generation from text-to-image data. Essentially, it leverages both textual and visual inputs to produce detailed and contextually rich images. This advancement is crucial for applications where text alone is insufficient to capture the user’s intent.
How Does MUMU Work?
- Multimodal Prompts:
MUMU uses prompts that combine text and images. For example, a prompt could be “a picture of a man and his dog in an animated style” where the words “man,” “dog,” and “animated style” are accompanied by corresponding images. This allows MUMU to generate a picture that faithfully integrates these elements.
Figure 1: An example of a multimodal prompt and the resulting image generated by MUMU. - Dataset Bootstrapping:
The dataset for training MUMU is created by extracting meaningful image crops from image captions of synthetically generated and publicly available text-image data. This method ensures that the model learns to associate specific parts of images with their corresponding textual descriptions.
Figure 2: Bootstrapping the multimodal dataset by extracting image crops from text-image data. - Model Architecture:
MUMU is built on a vision-language model encoder combined with a diffusion decoder. The model is trained on a single 8xH100 GPU node. Despite being trained only on image crops from the same image, MUMU can compose inputs from different images into a coherent output. For instance, an input of a realistic person and a cartoon will output the same person in the cartoon style.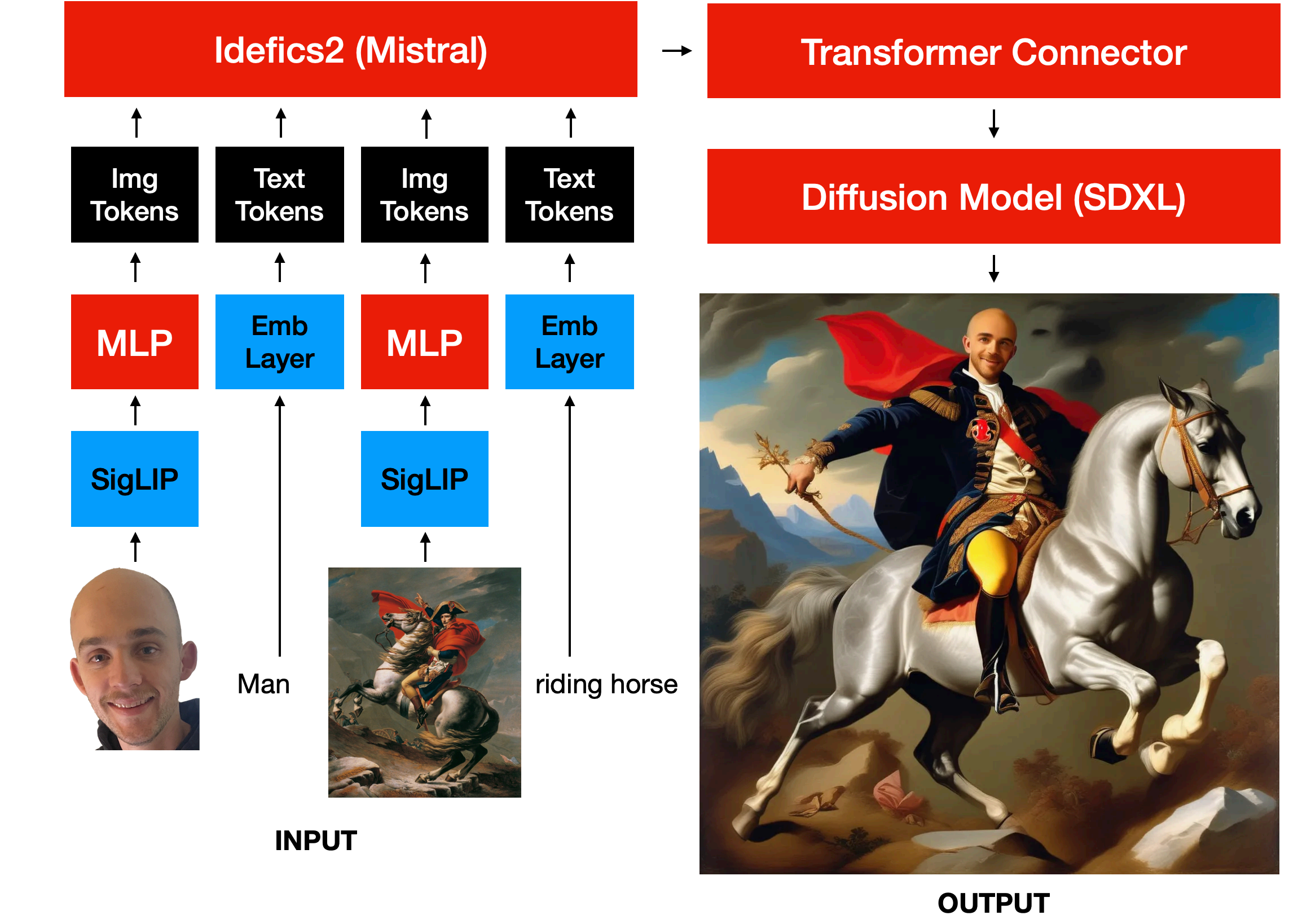
Figure 3: The full architecture of the MUMU model.
Key Features and Capabilities
- Style Transfer:
MUMU excels at transferring styles from one image to another. For example, it can take a realistic photo of a person and transform it into a cartoon version while maintaining the person’s features.
Figure 4: MUMU’s ability to harmonize different styles and objects in a single image. - Character Consistency:
The model can maintain character consistency across different contexts. For instance, if given an image of a person and a scooter, MUMU can generate an image of the person riding the scooter.
Figure 5: MUMU generates consistent characters across different scenarios. - Handling Diverse Inputs:
MUMU can combine various types of input images into a single coherent output. This ability makes it highly versatile for generating complex scenes.
Figure 6: MUMU’s capability to combine different input images harmoniously.
Challenges and Future Directions
While MUMU is a significant advancement, it still faces challenges such as preserving small details (e.g., fine facial features) and dealing with typical diffusion model artifacts like concept bleeding. Future improvements could focus on scaling the model, enhancing dataset quality, and refining the image tokenization process.

Figure 7: Challenges faced by MUMU, such as concept bleeding and detail preservation.
- Style Transfer Performance:
MUMU can perform style transfer by applying the style of one image to the content of another. However, it struggles with certain abstract styles, particularly when translating human faces into these styles.
Figure 8: Successful and less successful examples of style transfer performed by MUMU. - Community Fine-Tunes:
MUMU is compatible with existing community fine-tunes for SDXL. This means it can be merged with other stylistic models to generate images in specific styles without additional training.
Figure 9: MUMU’s compatibility with community fine-tunes to generate images in various styles. - Character Consistency Comparison:
MUMU is compared with InstantID, a model specialized for identity-preserving face generation. While InstantID excels at facial details, MUMU performs better at maintaining non-facial details like hair and accessories.
Figure 10: Comparison between MUMU and InstantID in terms of character consistency. - Balancing Detail and Harmonization:
Achieving a balance between detail preservation and input harmonization is a key challenge. MUMU can handle diverse inputs but may lose some fine details in the process.
Figure 11: Examples showing how MUMU balances detail preservation and harmonization of inputs. - Evaluation of Multimodal CLIP Scores:
Evaluation metrics are crucial for measuring model performance. MUMU’s performance is assessed using multimodal CLIP scores and face embedding similarity, highlighting areas for improvement.
Figure 12: Evaluation of MUMU’s performance using multimodal CLIP scores and face embedding similarity.
Conclusion
MUMU represents a promising step towards more sophisticated and versatile AI-driven image generation. By integrating multimodal inputs, it opens up new possibilities for creative applications, from generating consistent character images to performing complex style transfers. As research continues, MUMU and similar models are likely to become essential tools in the realm of digital creativity.
For detailed technical insights and additional examples, refer to the figures and explanations provided in the original MUMU technical report.