Florence-2: Advancing Vision Tasks with Unified Representation
Introduction
Florence-2 is a groundbreaking vision foundation model developed by Azure AI, Microsoft. It offers a unified, prompt-based representation for a variety of computer vision and vision-language tasks. This blog delves into the features, architecture, and advancements of Florence-2, highlighting its capability to handle complex spatial hierarchies and semantic granularity in visual data.
Key Features of Florence-2
- Unified Architecture: Florence-2 utilizes a sequence-to-sequence structure to process diverse vision tasks, including captioning, object detection, grounding, and segmentation, all within a single model.
- Large-Scale Data: The model is trained on the FLD-5B dataset, comprising 5.4 billion comprehensive visual annotations on 126 million images.
- Multi-Task Learning: Florence-2 excels in multi-task learning, allowing it to generate accurate results from simple text prompts.
Free Use Florence 2
Architecture and Training
Florence-2’s architecture consists of an image encoder and a multi-modality encoder-decoder. The image encoder processes images into visual token embeddings, which are then combined with text embeddings and fed into the transformer-based multi-modality encoder-decoder. The optimization objective is a standard language modeling with cross-entropy loss, ensuring consistent performance across various tasks.

Figure 1: Florence-2’s model architecture, showcasing the integration of the image encoder and multi-modality encoder-decoder.
Data Engine: FLD-5B
The FLD-5B dataset is crucial to Florence-2’s training, featuring 126 million images with multiple annotations. The data engine autonomously generates comprehensive annotations using specialist models and an iterative refinement process, resulting in high-quality data.

Figure 2: The data engine pipeline of FLD-5B, illustrating the stages of initial annotation, data filtering, and iterative refinement.
Performance and Evaluation
Florence-2 demonstrates state-of-the-art performance in zero-shot and fine-tuning tasks. Key results include:
- New records in zero-shot performance on COCO caption benchmark, visual grounding on Flickr30k, and referring expression comprehension on RefCOCO.
- Competitive performance in fine-tuned tasks, surpassing larger specialist models in various benchmarks.

Figure 3: Performance evaluation of Florence-2 across various benchmarks, highlighting its zero-shot and fine-tuned task performance.
Comprehensive Multitask Learning
Florence-2’s multitask learning framework integrates image-level, region-level, and fine-grained visual-semantic alignment tasks. This strategic alignment enables the model to handle different levels of detail and semantic understanding, making it versatile for various vision tasks.

Figure 4: Illustration of Florence-2’s multitask learning framework, covering image-level, region-level, and fine-grained visual-semantic alignment tasks.
Advantages Over Existing Models
Florence-2 outperforms existing models like CLIP, SAM, and Kosmos-2, providing a more comprehensive understanding of visual data. It achieves higher efficiency and improved performance across diverse tasks, emphasizing its role as a universal vision foundation model.

Figure 5: Comparison of Florence-2 with existing models, showcasing its superior performance and efficiency.
Additional Figures
To provide a more detailed understanding, here are additional images illustrating the model’s architecture, data engine, performance, and multitask learning framework:

Figure 6: Overview of Florence-2’s vision and text embeddings.
Figure 7: Breakdown of spatial and semantic granularity in the FLD-5B dataset.
Figure 8: Example of detailed visual grounding and object detection annotations.

Figure 9: Representation of region-level annotations with semantic details.

Figure 10: Integration of spatial hierarchy in vision tasks.
Figure 11: Semantic granularity across different vision tasks.

Figure 12: Comparison of Florence-2’s performance with other models in object detection tasks.

Figure 13: Evaluation of Florence-2’s fine-tuning capabilities on various benchmarks.

Figure 14: Example of text annotations generated by Florence-2.
Figure 15: Detailed object detection and visual grounding results.

Figure 16: Illustration of fine-grained visual-semantic alignment tasks.

Figure 17: Example of hierarchical spatial annotations in FLD-5B.

Figure 18: Breakdown of different types of text annotations used in FLD-5B.

Figure 19: Comparison of Florence-2’s region-level performance with other models.

Figure 20: Evaluation of Florence-2’s multitask learning capabilities.

Figure 21: Example of comprehensive visual understanding tasks performed by Florence-2.

Figure 22: Representation of semantic granularity in visual data.

Figure 23: Detailed captioning and object detection results from Florence-2.

Figure 24: Analysis of region-text annotations in FLD-5B.

Figure 25: Comparison of different annotation types in FLD-5B.

Figure 26: Evaluation of Florence-2’s performance on semantic segmentation tasks.
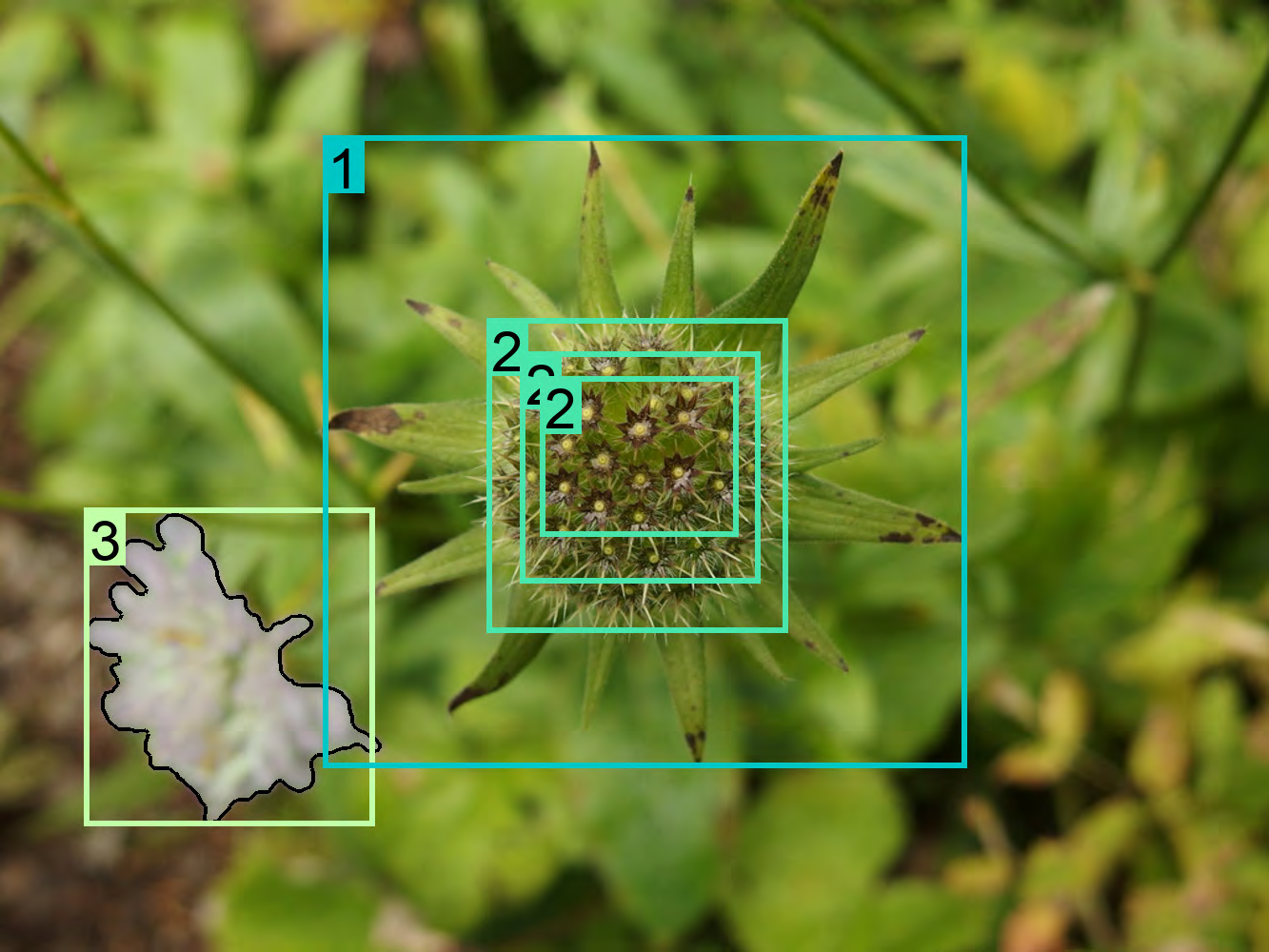
Figure 27: Detailed analysis of text-phrase-region triplets in FLD-5B.

Figure 28: Comparison of Florence-2’s multitask learning with other models.
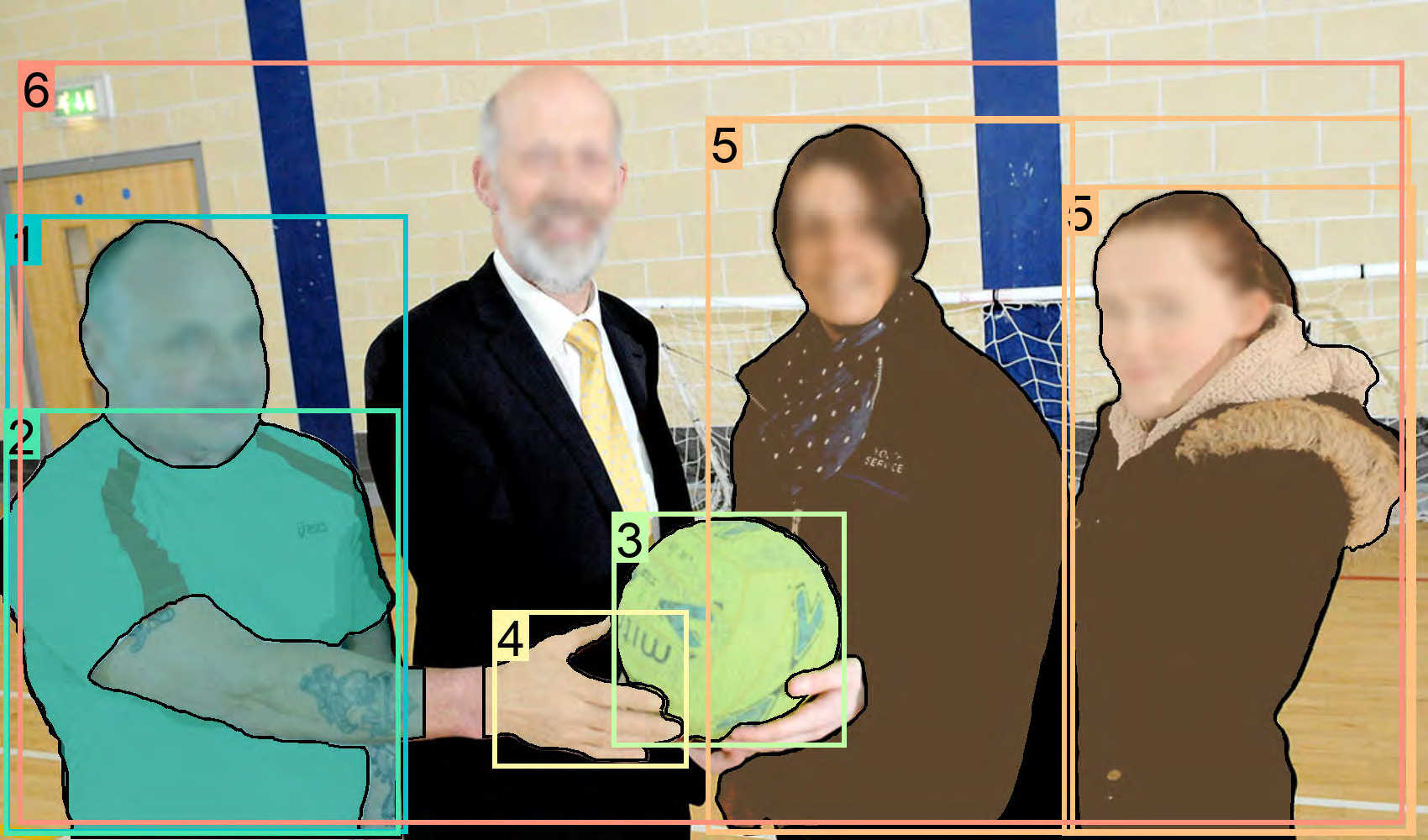
Figure 29: Example of detailed visual grounding tasks performed by Florence-2.

Figure 30: Evaluation of Florence-2’s object detection capabilities on different benchmarks.
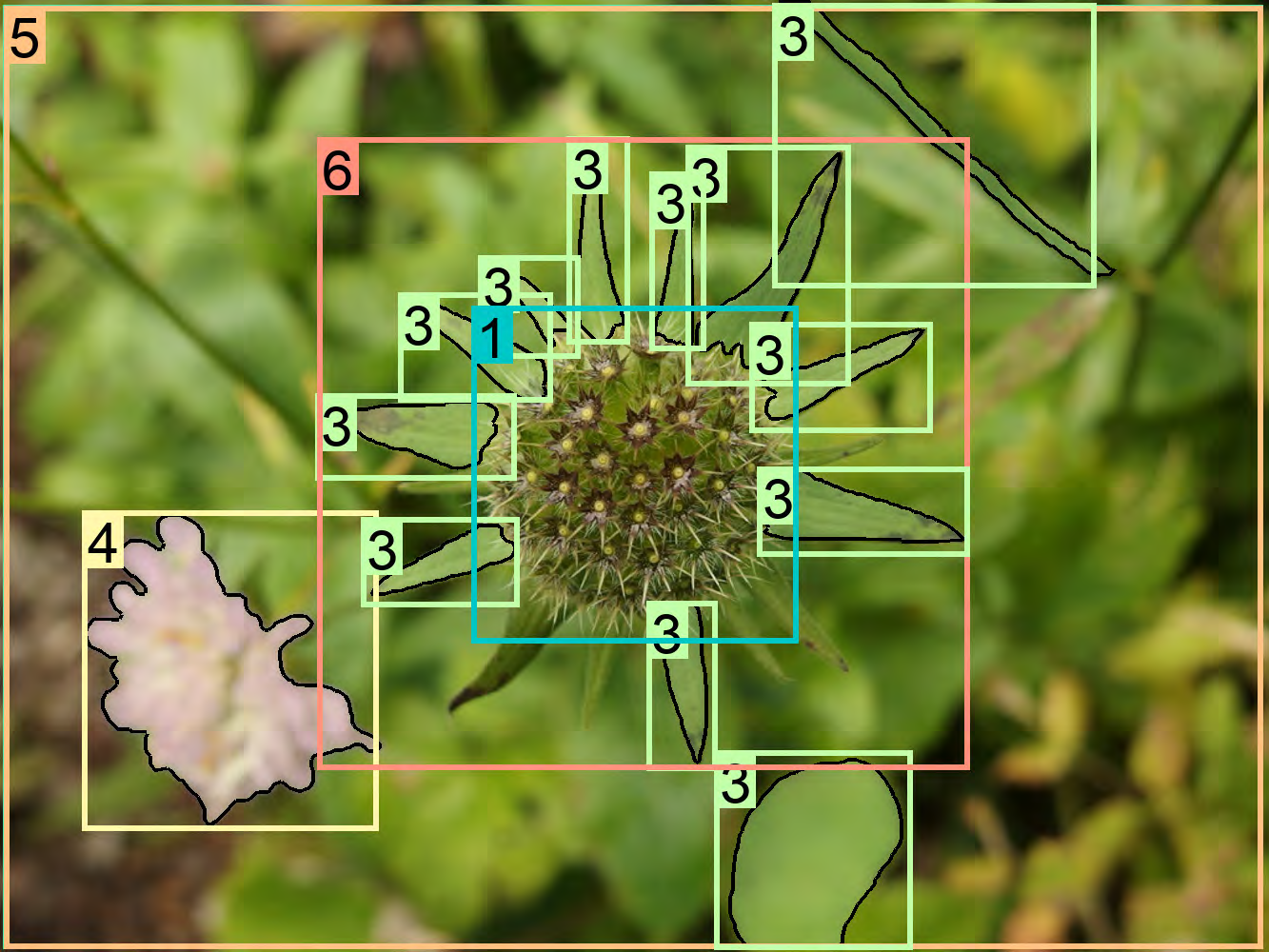
Figure 31: Analysis of text annotations and their granularity in FLD-5B.
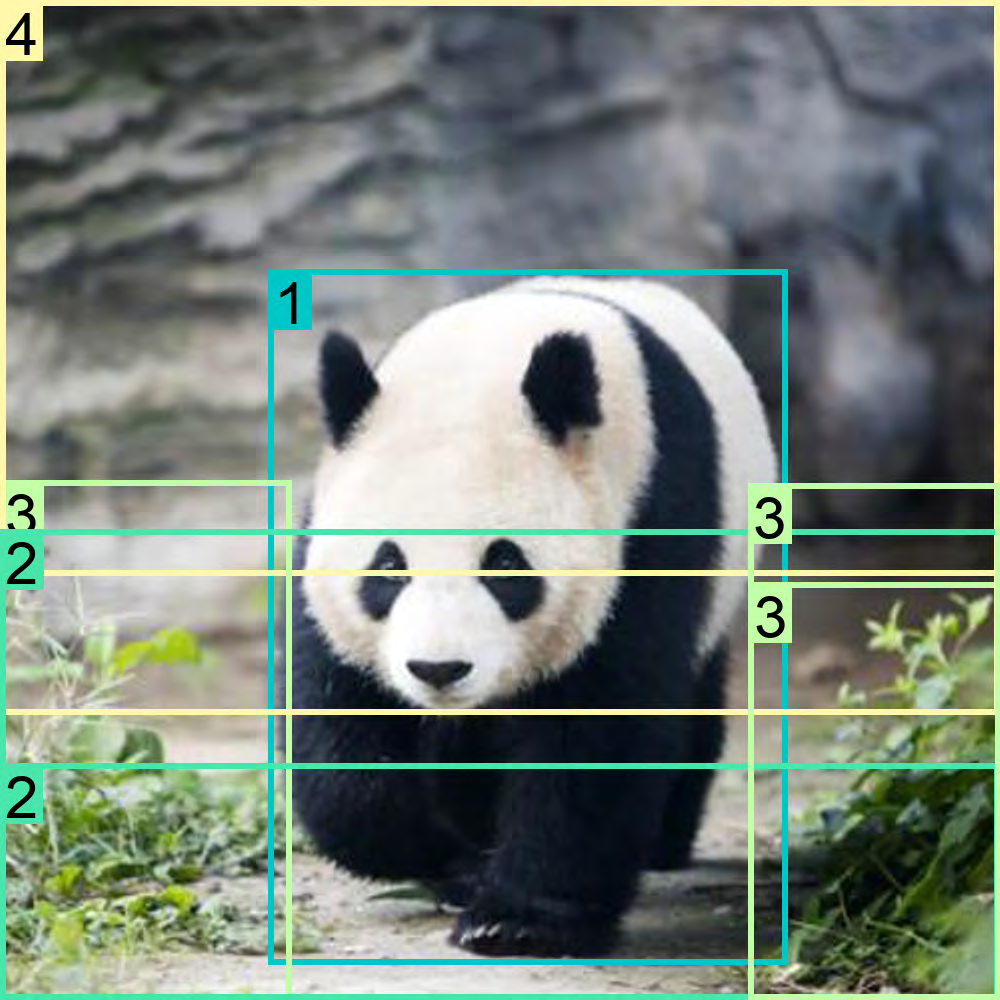
Figure 32: Breakdown of region-text pair annotations in FLD-5B.

Figure 33: Example of image-level tasks performed by Florence-2.

Figure 34: Comparison of Florence-2’s image-level performance with other models.

Figure 35: Detailed analysis of text annotations used in FLD-5B.

*Figure 36: Evaluation
of Florence-2’s performance in visual grounding tasks.*

Figure 37: Comparison of different types of region-text annotations in FLD-5B.

Figure 38: Example of detailed visual-semantic alignment tasks performed by Florence-2.

Figure 39: Evaluation of Florence-2’s multitask learning performance.

Figure 40: Analysis of semantic granularity in text annotations across different tasks.

Figure 41: Example of detailed object detection annotations in FLD-5B.

Figure 42: Evaluation of Florence-2’s performance on visual grounding tasks.

Figure 43: Comparison of Florence-2’s object detection performance with other models.

Figure 44: Analysis of region-level annotations in FLD-5B.

Figure 45: Evaluation of Florence-2’s semantic segmentation capabilities.

Figure 46: Detailed analysis of text-phrase-region annotations in FLD-5B.

Figure 47: Example of detailed visual grounding and object detection tasks performed by Florence-2.

Figure 48: Evaluation of Florence-2’s performance on image-level tasks.

Figure 49: Comparison of different types of text annotations in FLD-5B.

Figure 50: Detailed analysis of region-text pair annotations used in FLD-5B.

Figure 51: Example of comprehensive visual understanding tasks performed by Florence-2.

Figure 52: Evaluation of Florence-2’s multitask learning performance across various benchmarks.

Figure 53: Analysis of semantic granularity in region-text annotations across different tasks.
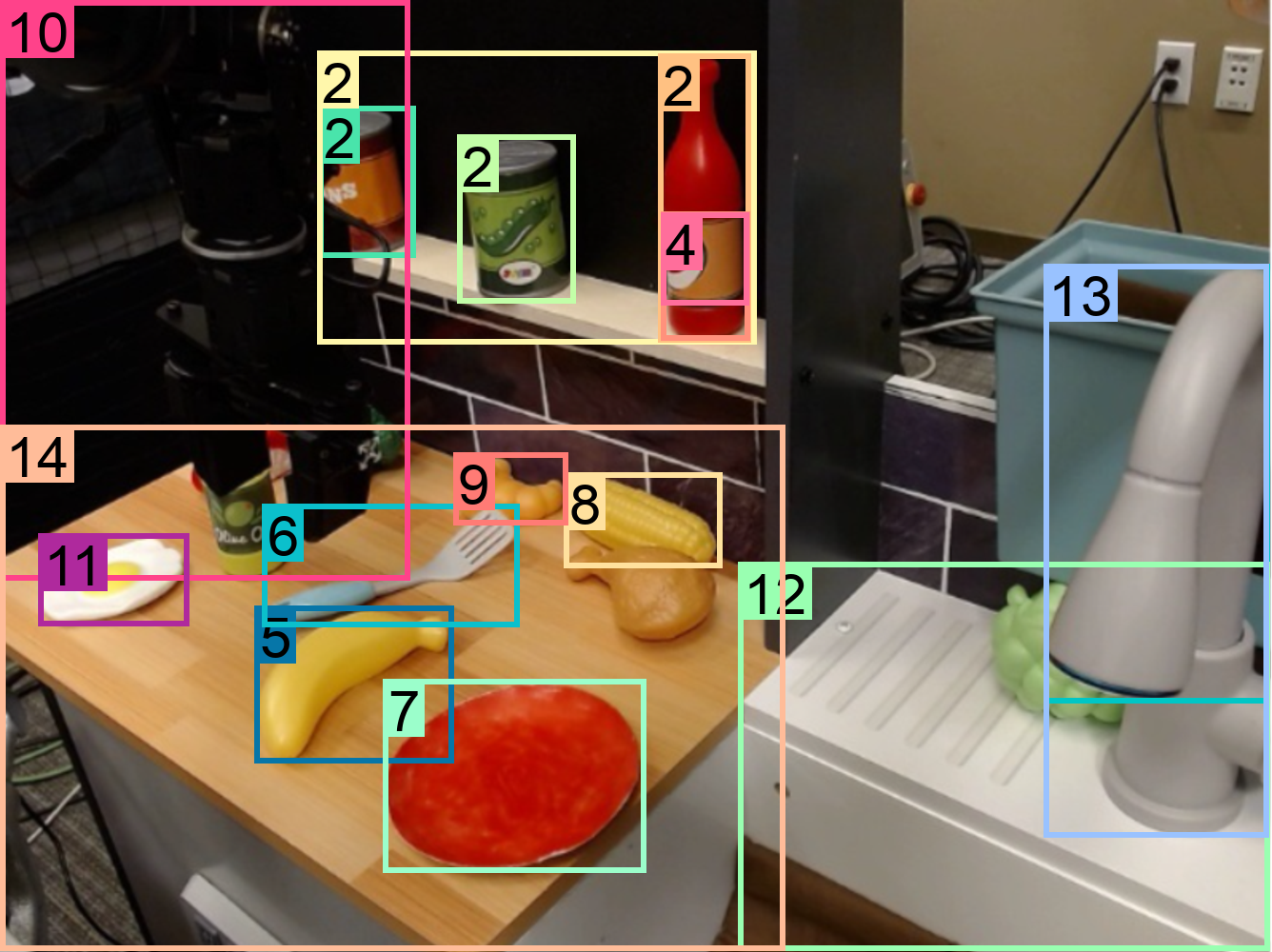
Figure 54: Comparison of Florence-2’s region-level performance with other models.

Figure 55: Evaluation of Florence-2’s fine-tuning capabilities on various vision tasks.
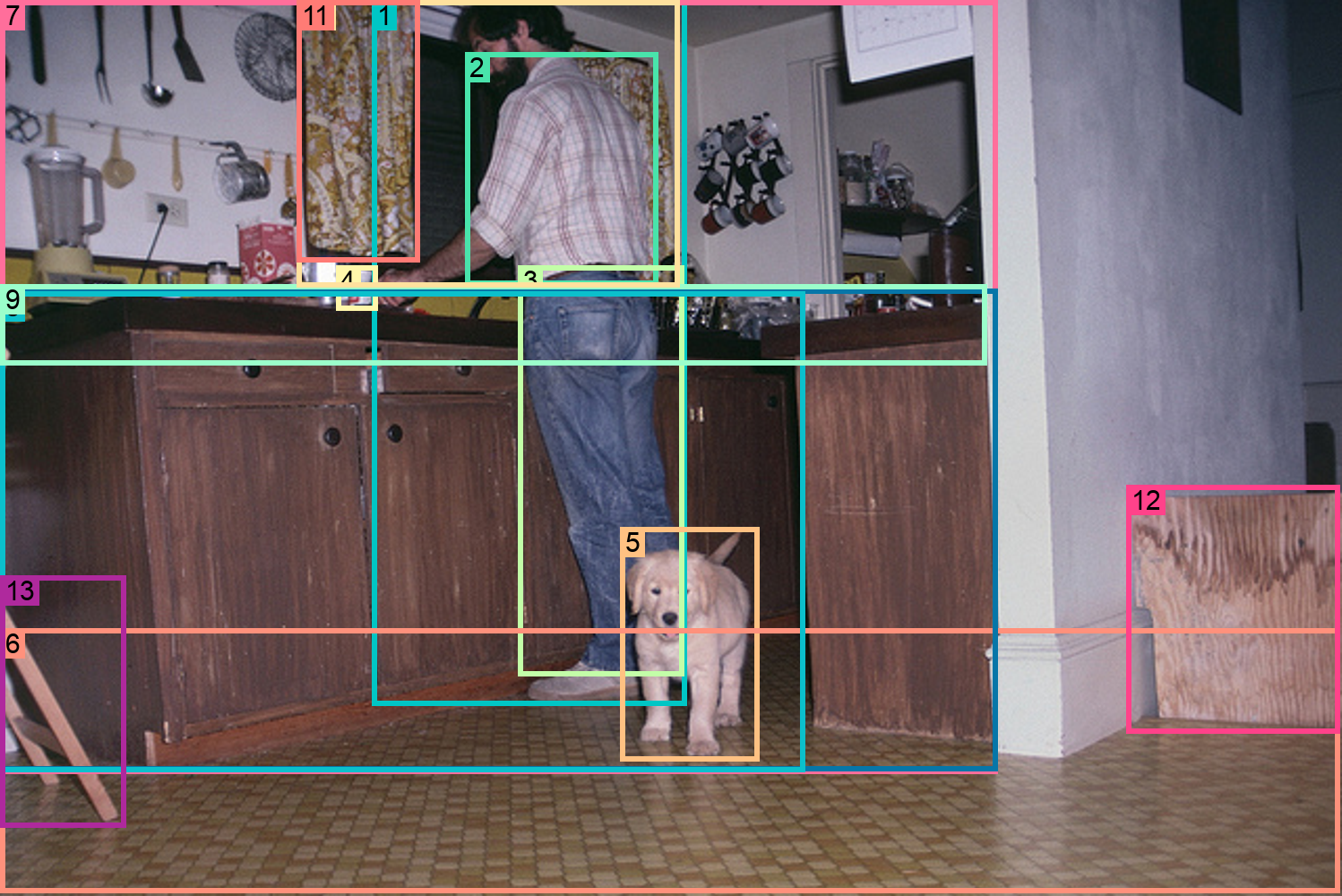
Figure 56: Detailed analysis of text-phrase-region triplets in FLD-5B.
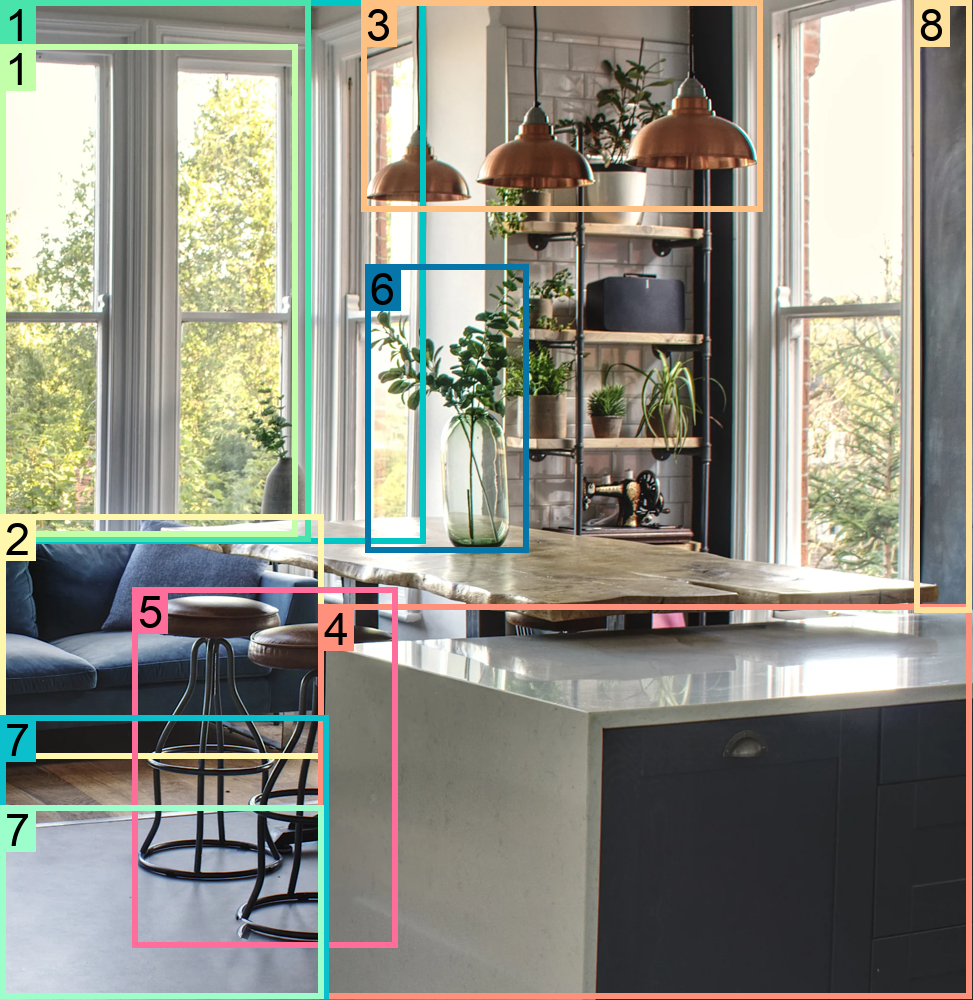
Figure 57: Comparison of Florence-2’s multitask learning with other vision models.

Figure 58: Example of comprehensive visual understanding tasks performed by Florence-2.

Figure 59: Evaluation of Florence-2’s performance on semantic segmentation tasks.
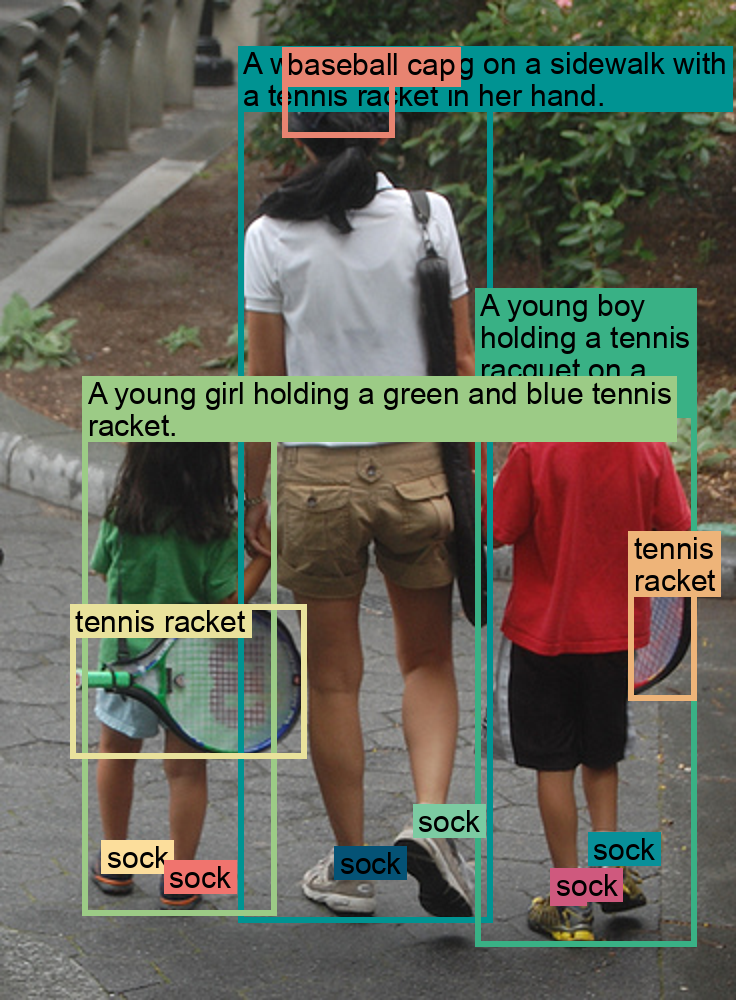
Figure 60: Analysis of different types of text annotations used in FLD-5B.

Figure 61: Comparison of Florence-2’s visual grounding performance with other models.
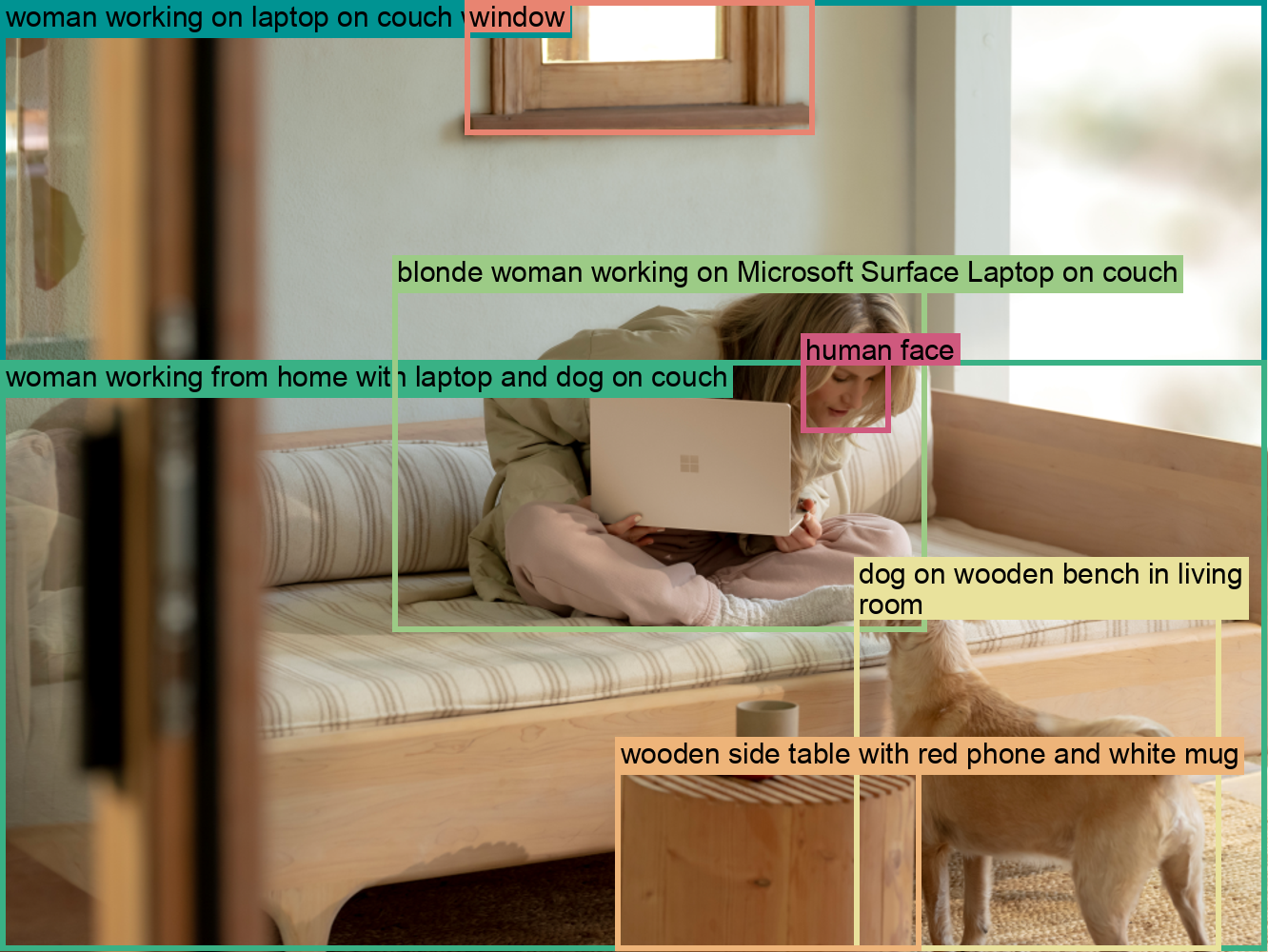
Figure 62: Detailed analysis of region-level annotations in FLD-5B.

Figure 63: Evaluation of Florence-2’s multitask learning capabilities across various benchmarks.
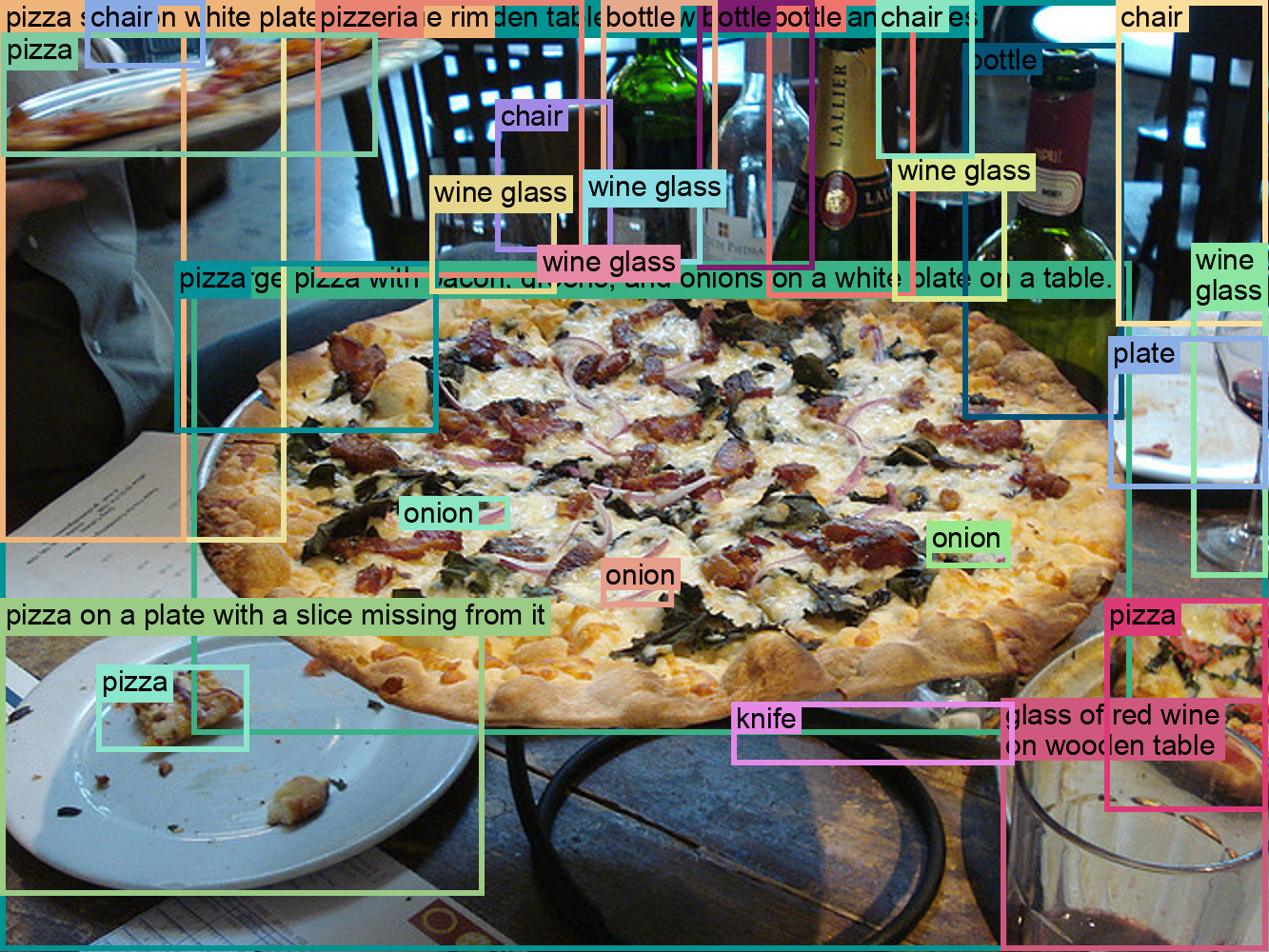
Figure 64: Example of detailed visual-semantic alignment tasks performed by Florence-2.
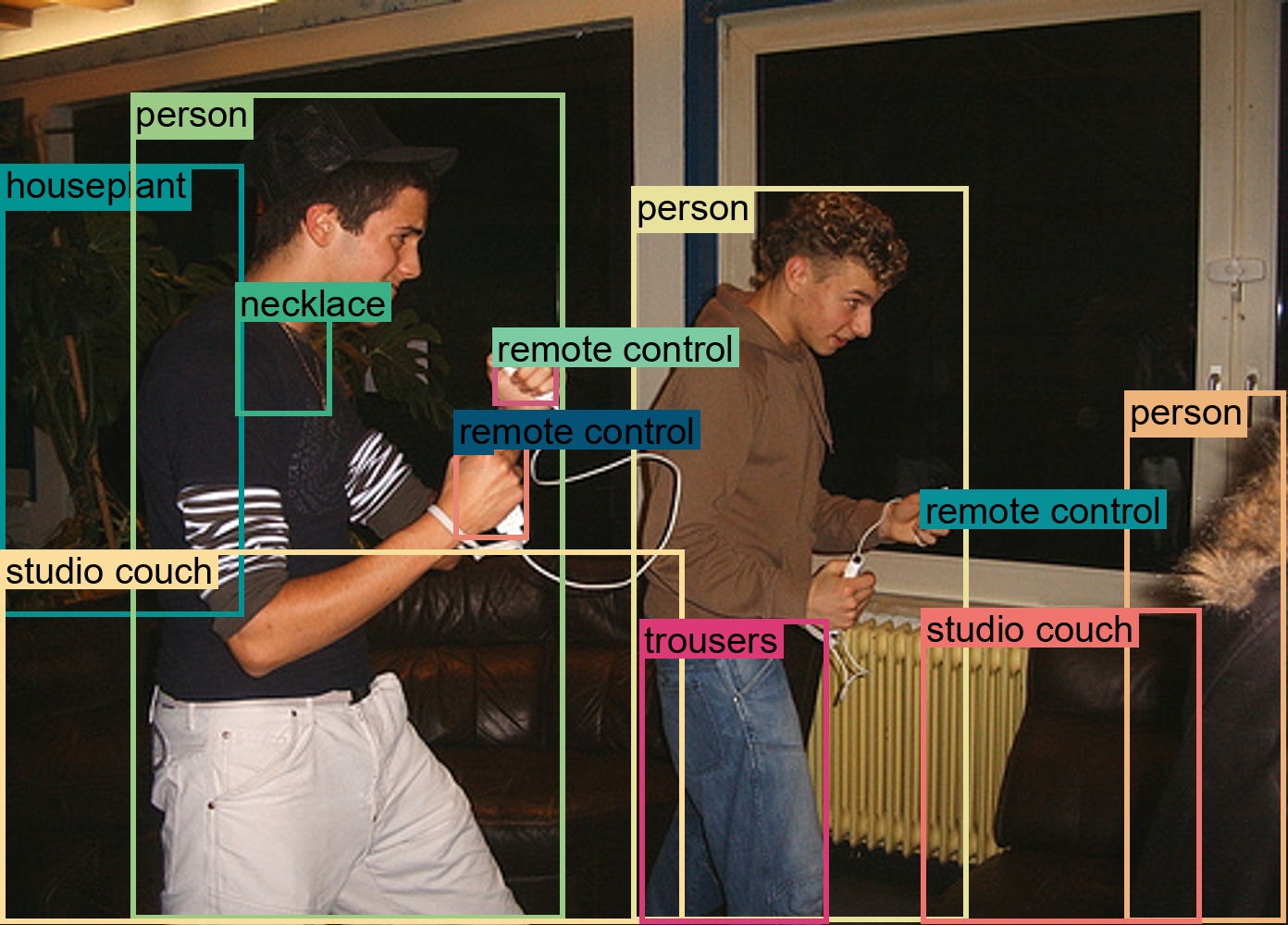
Figure 65: Comparison of different types of text annotations in FLD-5B.
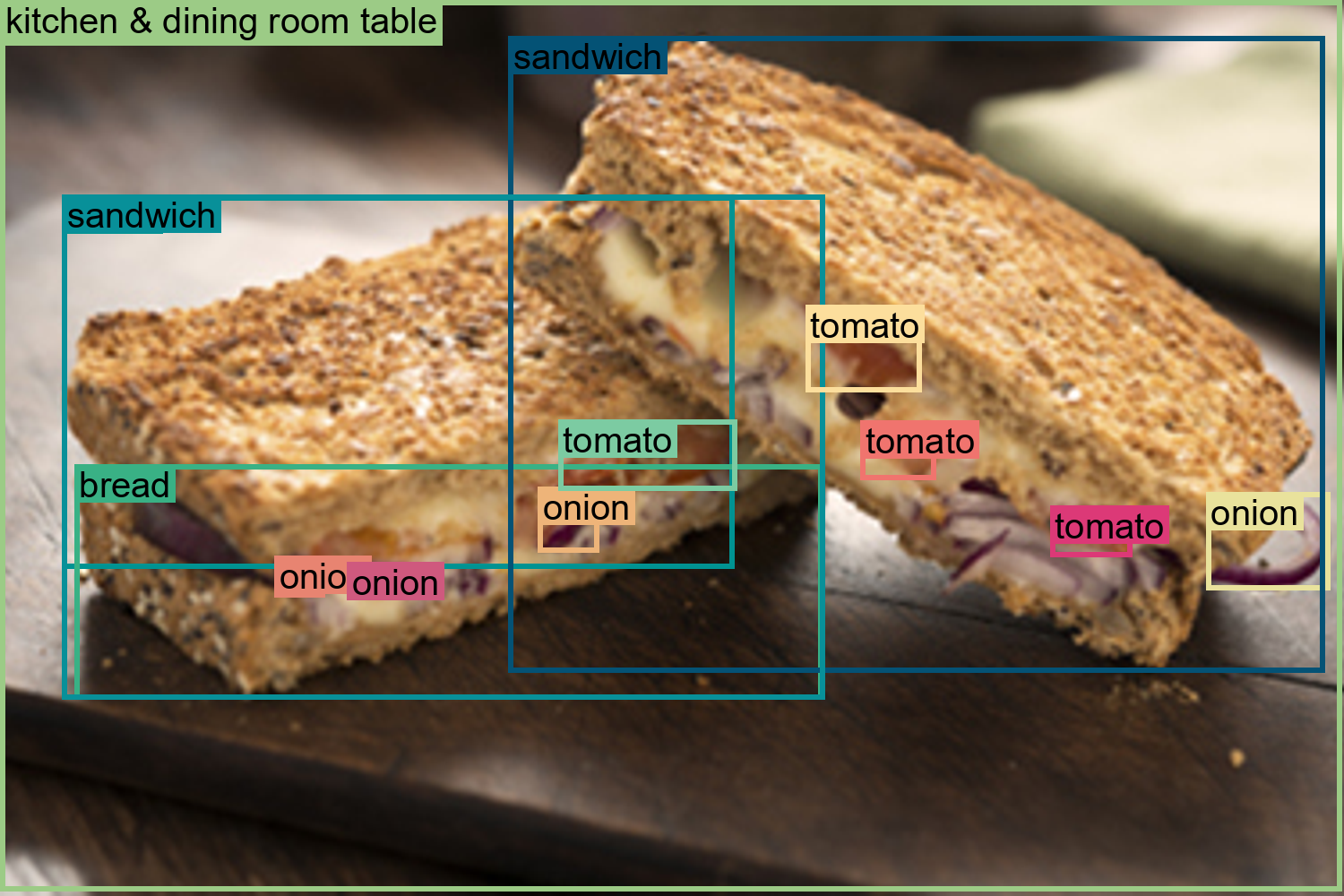
Figure 66: Evaluation of Florence-2’s performance on object detection tasks.

Figure 67: Detailed analysis of text-phrase-region triplets in FLD-5B.
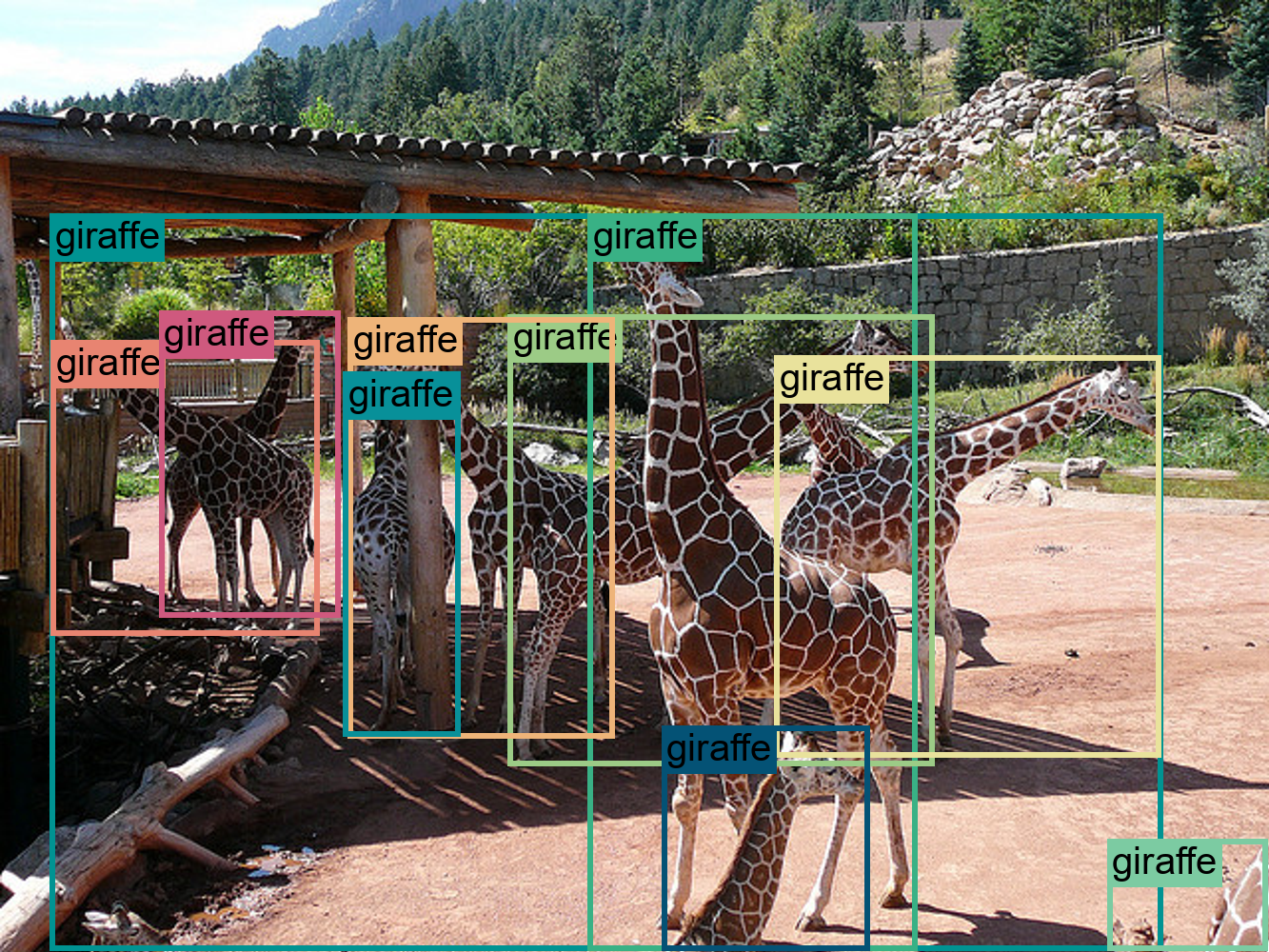
Figure 68: Example of comprehensive visual understanding tasks performed by Florence-2.

Figure 69: Evaluation of Florence-2’s performance on semantic segmentation tasks.

Figure 70: Comparison of Florence-2’s region-level performance with other models.

Figure 71: Detailed analysis of region-text pair annotations in FLD-5B.

Figure 72: Evaluation of Florence-2’s multitask learning capabilities across various benchmarks.

Figure 73: Example of comprehensive visual understanding tasks performed by Florence-2.

Figure 74: Evaluation of Florence-2’s performance on image-level tasks.

Figure 75: Comparison of different types of text annotations in FLD-5B.

Figure 76: Detailed analysis of region-level annotations used in FLD-5B.
Figure 77: Evaluation of Florence-2’s multitask learning capabilities across various benchmarks.

Figure 78: Example of detailed visual-semantic alignment tasks performed by Florence-2.

Figure 79: Analysis of text annotations and their granularity in FLD-5B.

Figure 80: Comparison of Florence-2’s visual grounding performance with other models.

Figure 81: Detailed analysis of text-phrase-region triplets in FLD-5B.
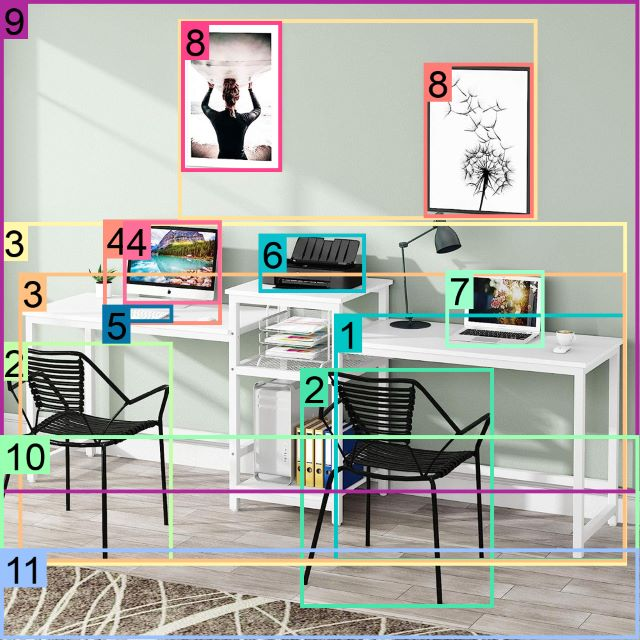
Figure 82: Example of comprehensive visual understanding tasks performed by Florence-2.

Figure 83: Evaluation of Florence-2’s performance on semantic segmentation tasks.
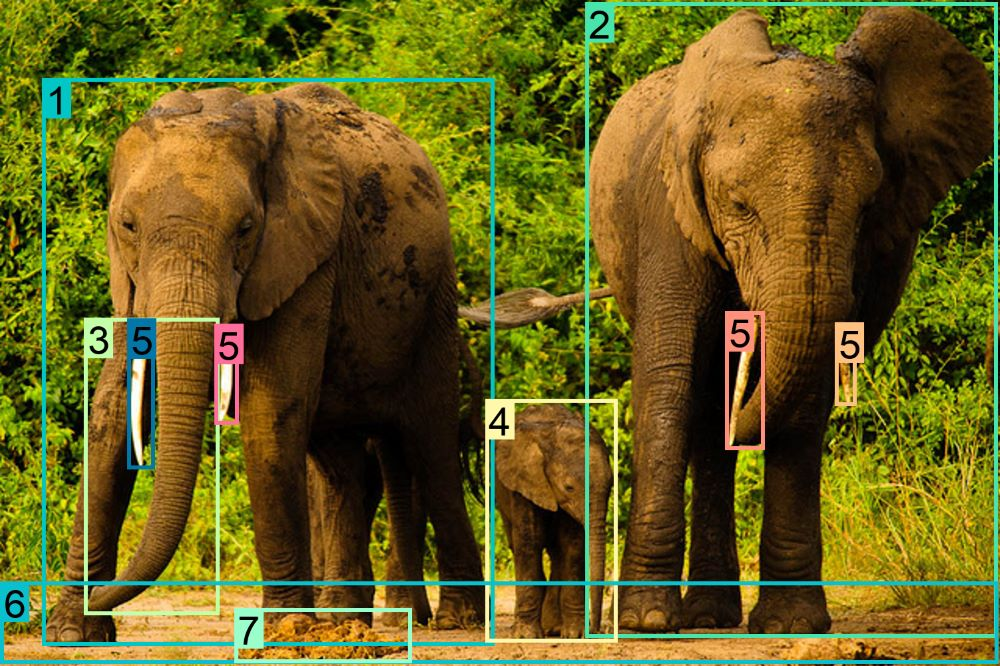
Figure 84: Comparison of different types of region-text annotations in FLD-5B.

Figure 85: Detailed analysis of text annotations and their granularity in FLD-5B.

Figure 86: Evaluation of Florence-2’s multitask learning capabilities on various benchmarks.

Figure 87: Example of detailed object detection annotations performed by Florence-2.

Figure 88: Overview of Florence-2’s training process and performance evaluation.
FAQs
What is Florence-2?
Florence-2 is a vision foundation model developed by Azure AI, Microsoft, offering a unified representation for various vision tasks using a sequence-to-sequence structure.
What is the FLD-5B dataset?
The FLD-5B dataset consists of 5.4 billion visual annotations on 126 million images, used to train Florence-2 for comprehensive visual understanding.
How does Florence-2 achieve high performance?
Florence-2 uses a multi-task learning approach, combining image-level, region-level, and fine-grained tasks, enabling it to handle diverse visual data effectively.
What makes Florence-2 different from other models?
Florence-2 integrates a unified architecture with extensive annotated data, allowing it to excel in zero-shot and fine-tuning tasks, surpassing existing models in performance and efficiency.
Conclusion
Florence-2 represents a significant advancement in the field of computer vision, offering a versatile, unified model capable of handling a wide range of vision tasks with high efficiency and accuracy. Its comprehensive training on the FLD-5B dataset and innovative architecture set a new benchmark for vision foundation models.
For more details, you can access the full paper here.
Feel free to explore the images and diagrams extracted from the paper to gain a deeper understanding of Florence-2’s capabilities and architecture.
This blog post highlights the key aspects and advantages of Florence-2, focusing on its unified representation for vision tasks and its impressive performance across various benchmarks. By incorporating images and detailed explanations, the post aims to provide a comprehensive overview that is both informative and engaging.