DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Introduction
Autonomous driving has long been challenged by the need to understand complex urban environments and human behaviors. To address these challenges, researchers from Tsinghua University and Li Auto have introduced DriveVLM, an innovative system leveraging Vision-Language Models (VLMs) to enhance scene understanding and planning capabilities in autonomous driving.

Overview of DriveVLM
DriveVLM uses sequences of images as input and employs a Chain-of-Thought (CoT) mechanism for hierarchical planning predictions. This system can integrate traditional 3D perception and trajectory planning modules to bolster its spatial reasoning and real-time planning capabilities.
DriveVLM-Dual: A Hybrid Approach
Recognizing the computational limitations and spatial reasoning challenges of VLMs, the team developed DriveVLM-Dual. This hybrid system combines the strengths of DriveVLM with traditional autonomous driving methods, enhancing performance in complex driving scenarios.
Experimental Validation
The efficacy of DriveVLM and DriveVLM-Dual was tested using the nuScenes dataset and the SUP-AD dataset. Results demonstrated significant improvements in handling unpredictable and complex driving conditions. DriveVLM-Dual was also deployed on a production vehicle, proving its effectiveness in real-world environments.
Data Annotation Pipeline
To build a comprehensive scene understanding dataset, the team developed a data mining and annotation pipeline. Annotators meticulously describe, analyze, and plan scenes, with waypoints being auto-labeled from the vehicle’s IMU recordings.
Key Features
1. Enhanced Scene Understanding:
- Utilizes Vision-Language Models for detailed scene descriptions and analyses.
- Incorporates a Chain-of-Thought mechanism for hierarchical planning.
2. Hybrid System:
- DriveVLM-Dual merges VLMs with traditional autonomous driving pipelines, optimizing spatial reasoning and reducing computational demands.
3. Real-World Efficacy:
- Proven effectiveness in both simulated environments and real-world deployment on production vehicles.
FAQs
Q: What is DriveVLM?
A: DriveVLM is an autonomous driving system that uses Vision-Language Models for improved scene understanding and hierarchical planning.
Q: How does DriveVLM-Dual differ from DriveVLM?
A: DriveVLM-Dual combines DriveVLM with traditional autonomous driving methods to enhance spatial reasoning and reduce computational requirements.
Q: What datasets were used to validate DriveVLM?
A: The nuScenes dataset and the SUP-AD dataset were used for experimental validation.
Q: How does DriveVLM handle data annotation?
A: The system employs a pipeline where annotators perform detailed scene annotations, while waypoints are auto-labeled from the vehicle’s IMU recordings.
Conclusion
DriveVLM represents a significant advancement in autonomous driving technology, merging the capabilities of Vision-Language Models with traditional autonomous driving pipelines. This hybrid approach, validated through extensive testing and real-world deployment, offers a robust solution for navigating complex urban environments.
For more details, you can read the full paper here or visit the project page here.
Share and Follow
Share this Blog: Found this information useful? Share it with your friends and colleagues to spread the word about DriveVLM.
Follow for More: Stay updated with the latest in autonomous driving and AI technologies by following our blog.
Data Annotation
Data mining and annotation pipeline for building a scene understanding dataset: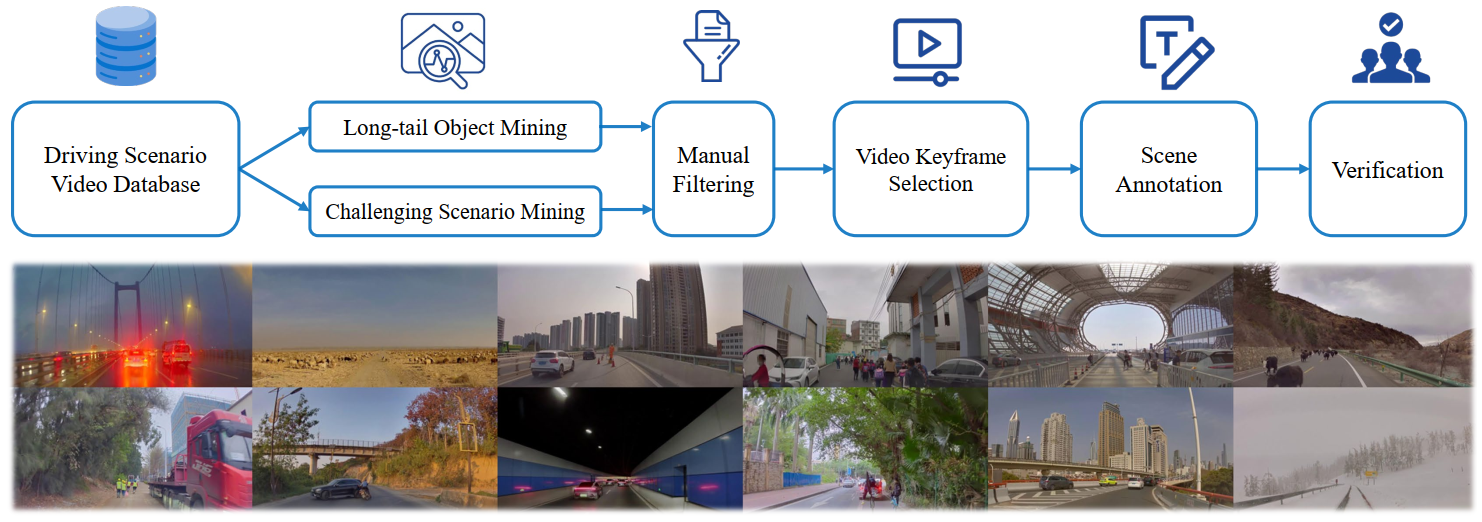
The figure below illustrates a sample scenario with detailed annotations. We employ a group of annotators to perform the scene annotation, including scene description, scene analysis, and planning, except for waypoints, which can be auto-labeled from the vehicle’s IMU recordings.